ECF939 : Science des données avancées
L’ensemble des exercices présentés dans ce notebook sera traité sur R.
Méthode CART
Exercice 1 : Iris Data
- Charger le jeu de données
iris. Afficher les premières lignes et effectuer un résumé rapide des données.
- Séparer le jeu de données en deux échantillons :
- un échantillon d’entraînement contenant 70% des données;
- un échantillon de validation contenant 30% des données (i.e. les données restantes).
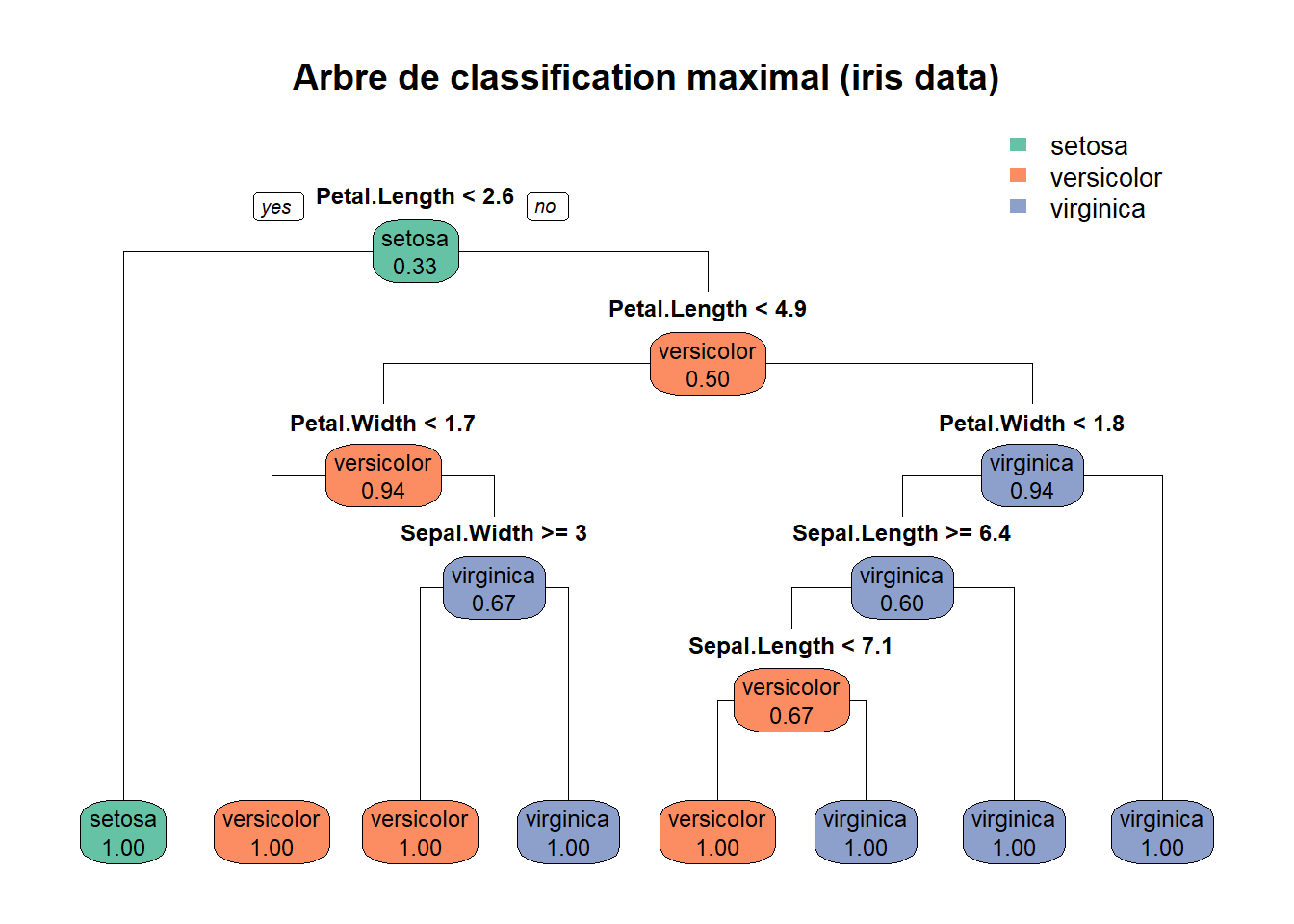
- On cherche à prédire le type de fleur (Species) en fonction des autres variables. Sur l’échantillon d’entraînement, faire pousser un arbre de classification maximal à l’aide de la fonction
rpart(), issue du package du même nom.
- A l’aide de la fonction
rpart.plot(), issue du package du même nom, représenter l’arbre de classification ainsi crée.
- On s’intéresse dorénavant à la complexité de l’arbre.
A l’aide de la fonction printcp(), afficher la complexité de la suite d’arbres construits pour l’arbre maximal.
Afficher ensuite, avec la fonction plotcp() les erreurs obtenues par validation croisée dans la recherche du meilleur arbre (au sens de la fonction de coût)
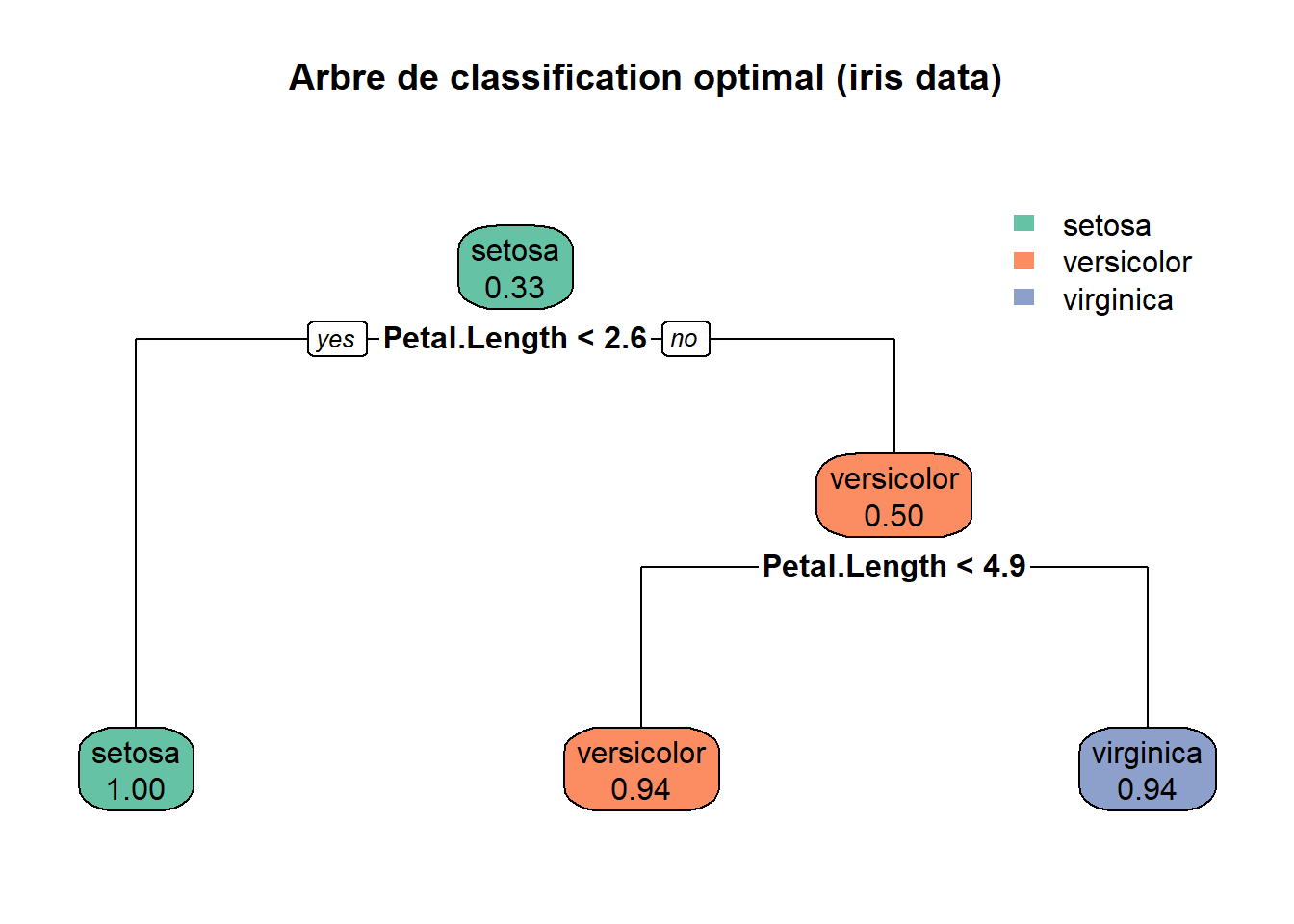
- Déterminer ensuite l’arbre optimal en utilisant la fonction
prune(). On pourra d’abord déterminer la complexité optimalecp_opt.
- Afficher l’arbre obtenu
- Appliquer l’arbre de classification obtenu sur l’échantillon test, et calculer le pourcentage de mauvaises classifications obtenues. On pourra utiliser la fonction
predict().
Exercice 2 : Prédiction de ventes
Dans cet exercice, on considère le jeu de données food_sales.csv, disponible sur connect.
On s’intéresse ici aux ventes d’une marque de céréales, que l’on cherche à prédire en fonction de plusieurs variables. Le jeu de données représente ainsi 11 variables mesurées dans 400 magasins de communes différentes (les unités choisies ici sont arbitraires).
- Sales : quantité de céréales vendues dans le magasin.
- CompPrice : prix de vente moyen des céréales concurrentes dans le magasin.
- Income : Revenu moyen des consommateurs dans la commune du magasin.
- Advertising : Montant dépensé en publicité dans la commune du magasin.
- Population : Population de la commune.
- Price : Prix de vente des céréales.
- ShelfQuality : Qualité de placement des céréales dans le magasin.
- StoreSize : Taille du magasin.
- StoreAge : Age du magasin.
- Urban : Si le magasin est situé en zone urbaine ou non.
- Region : Zone géographique du mgasin.
- Charger le jeu de données, et en dresser un rapide résumé.
- Séparer les données en un jeu d’entraînement contenant 70% des données, et un jeu de test en contenant 30%.
- Sur le jeu d’entraînement, faire pousser un arbre de régression profond donnant la quantité de céréales vendues en fonction des autres variables. Représenter graphiquement cet arbre.
- Elaguer cet arbre pour avoir un arbre de régression optimal, et le représenter.
- Estimer le risque de la prévision obtenue par cet arbre sur le jeu de test.
Comparer ce risque avec celui obtenu en effectuant une simple régression linéaire.
Reprendre les questions précédentes, mais en faisant varier l’échantillon d’entraînement. Que constate-t-on ?